论文地址:https://arxiv.org/abs/2307.01952
代码地址:https://github.com/Stability-AI/generative-models
Contents
0. TL;DR
这篇论文的主要内容可以总结如下(来自https://papers.cool/arxiv/2307.01952):
- 模型介绍:提出了SDXL,这是一个用于文本到图像合成的潜在扩散模型,它是Stable Diffusion模型的改进版本。
- 架构和规模:SDXL采用了一个比之前版本大三倍的UNet骨干网络,增加了更多的注意力模块和更大的交叉注意力上下文。它使用了两个文本编码器,一个是OpenCLIP ViT-bigG,另一个是CLIP ViT-L。
- 新颖的条件方案:设计了多种新颖的条件方案,包括对模型进行图像尺寸和宽高比的条件设置,以及在数据加载时对裁剪参数进行条件设置。
- 细化模型:引入了一个用于改善样本视觉保真度的后处理图像到图像技术的细化模型。
- 性能评估:通过用户研究和与其他文本到图像生成模型的比较,展示了SDXL在图像合成方面的优势。
- 开放研究:为了促进开放研究和透明度,论文提供了模型的代码和权重。
- 未来工作:论文讨论了未来的研究方向,包括单阶段生成过程、文本合成能力的提升、架构的改进、降低推理成本和采样速度、处理社会和种族偏见、解决概念渗透问题以及改进长文本渲染。
- 实验结果:展示了SDXL在多个方面的性能,包括与之前版本的Stable Diffusion模型的比较、不同条件方案的效果、多宽高比训练的影响、自编码器的改进以及细化模型的效益。
总体而言,SDXL在提高图像合成质量、处理多样化图像尺寸和宽高比、改善细节和视觉保真度方面取得了显著进展,并推动了图像生成领域的开放研究。
1. Improving Stable Diffusion
1.1 Architecture & Scale
1.1.1 Modified UNet
Convolutional UNet作为Diffusion Model最为经典和基础的Backbone,也经历了一系列的演化:
- 2021.05 | Diffusion Models Beat GANs on Image Synthesis:加入Self-Attention,改进Upsampling Layers
- 2021.12 | High-Resolution Image Synthesis with Latent Diffusion Models:在Text-to-Image生成中引入Cross-Attention
- 2022.12 | Scalable Diffusion Models with Transformers:纯Transformer架构
SDXL也基本沿袭了上述改进,同时也参考了SimpleDiffusion中的一些设计,对原Stable Diffusion UNet中的Transformer blocks的分布进行了调整:
- 在分辨率最高的feature上去除了Transformer Block
- 在更低的两个分辨率的feature上依次使用2和10个Transformer Block
- 移除了最低分辨率的feature
1.1.2 Modified Text Encoder
在SDXL中,使用了两个Text Encoder:
SDXL中同时使用了两种Text Embedding:
- 两个Text Encoder倒数第二层的输出在通道维度进行拼接,作为一个更为强大的Text Embedding。
-
一个来自OpenCLIP ViT-bigG的Pooled Text Embedding。
以上两个种类的Text Embedding共同一起作为Cross Attention中的KV来源,由于Text Embeddings本身维度有提升,因此,整体计算量和参数量也会有所上升,Text Encoders的参数量为817M,整个UNet的参数量则提升至2.6B。
1.1.3 Architecture Comparison
SDXL相较于之前Stable Diffusion模型的结构改动如下表所示:

1.2 Micro-Conditioning
1.2.1 Conditioning the Model on Image Size
1.2.1.1 Minimal Size Requirement
LDM范式由于其两阶段的训练策略,使得其对于训练图片的尺寸有一个最低要求。
LDM具有两个阶段:
- 压缩感知阶段:使用一个VAE对输入图片进行压缩,一般是4倍或者是8倍下采样
- 去噪阶段:使用一个UNet完成去噪过程,此时,UNet内部还会有多个下采样stage
当输入图片分辨率过低时,比如低于256x256时,此时可能无法提供足够的信息来训练LDM。
之前有两个主要方案来解决上述问题,但各自都存在一些问题:
- 【Discarding】丢弃所有低于某个分辨率的图片(例如,对于Stable Diffusion 1.4/1.5来说,其会丢弃所有短边小于512的所有图片)
- SDXL深入分析了该方案的影响:
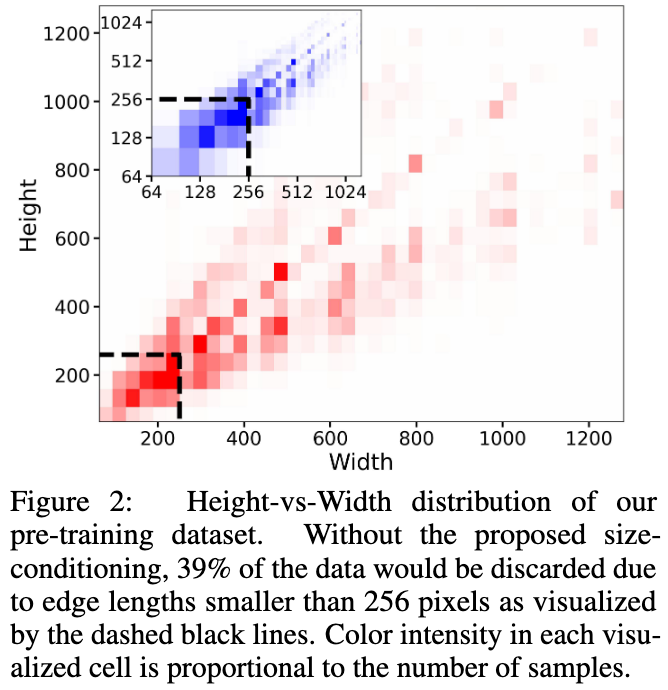
上图展示了SDXL预训练数据集中不同长宽比数据的分布。
对于丢弃方案来说,39%的数据都会被丢弃,这可能会导致效果以及泛化性的损失。
-
【Upsampling】将过小的图片上采样
- 对于上采样方案来说,其可能会在最终结果中引入一些上采样的artifacts,例如模糊。
SDXL则是采取了另一个方案:
- 【Conditioning on Image Size】将未做任何scaling前的Image的高和宽作为额外的条件c_{size}=(h_{original}, w_{origianl})输入到模型中,每一项都会单独使用一个Fourier Feature Encoding进行embedding,然后一起和Timestep embedding拼接后送入到模型中。
在测试阶段,用户可以通过size-conditioning来设定想要的可见分辨率。
1.2.1.2 Visually Assess Size Conditioning Effects

上图展示了size-conditioning对于图片生成的影响。当以更高的Image Size作为条件时,得到的样本质量更高。不过需要注意的是,后续SDXL在进行multi-aspect finetuning后,Size Conditioning的影响就没有那么明显了。
1.2.1.3 Quantitatively Assess Size Conditioning Effects
本文训练了三个模型:
- CIN-512-only:丢弃所有短边小于512的训练样本(最终得到70k的训练数据)
- CIN-nocond:保留所有样本,采用上采样策略处理分辨率较小的训练样本
- CIN-size-cond:在CIN-noncond基础上引入Size Conditioning策略
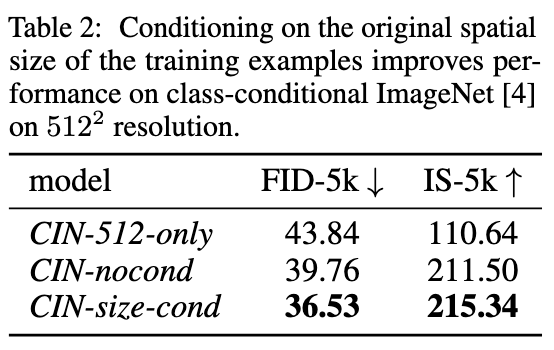
上图展示了三个模型在Validation测试集上的指标。
本文认为:
- CIN-512-only模型由于只在一个小训练集上进行训练,存在明显的过拟合问题
- CIN-nocond模型则是由于生成的样本比较模糊,从而导致FID下降
初步来看,SizeConditioning策略可以一定程度上提升Diffusion模型的表现。
1.2.2 Conditioning the Model on Cropping Parameters

之前的SD模型存在一个典型的failure mode:生成的目标可能会被Crop。例如在上图中,SD 1-5和SD 2-1中生成的猫咪的头部就存在被截断的现象。
这种现象的直观解释是:训练阶段的Random Cropping策略影响到了生成的样本。
为了解决这个问题,本文提出了CropParameterConditioning。
具体而言,在dataloading时,SDXL会均匀地采样Crop Coordinates c_{top}和c_{left}(两个整数,分别用于指示crop操作在height和width两个方向相较于原图左上角的偏移像素值),然后和ImageSizeConditioning操作类似,将两个数值各自通过Fourier Feature Embedding的方式进行编码后,拼接在一起作为c_{crop} embedding,作为额外的condition。
考虑到一般而言,大规模数据集通常是以目标为中心的,因此,SDXL在推理过程中设置 (c_{top}, c_{left})=(0, 0),从而从训练好的模型中获得以目标为中心的样本。
CropConditioning和SizeConditioning是可以同时使用的,下图给出了两者同时使用的一个算法pipeline:

下图展示了变化Crop Conditioning相关参数的效果。

1.3 Multi-Aspect Training
目前大部分的Text-to-Image模型的输出都是一个方图(512x512或者1024x1024),这和现实世界中更常用的16:9或者肖像格式比例的数据并不相符。
基于以上问题,SDXL进一步对模型进行了多长宽比微调:
参考该Blog,SDXL根据长宽比对数据进行了分桶,每个桶内的数据,在保持像素数目尽可能接近1024x1024的情况下,对长宽进行调整,每次都以64的倍数进行调整。
下图给出了SDXL在微调阶段使用的长宽比参数:
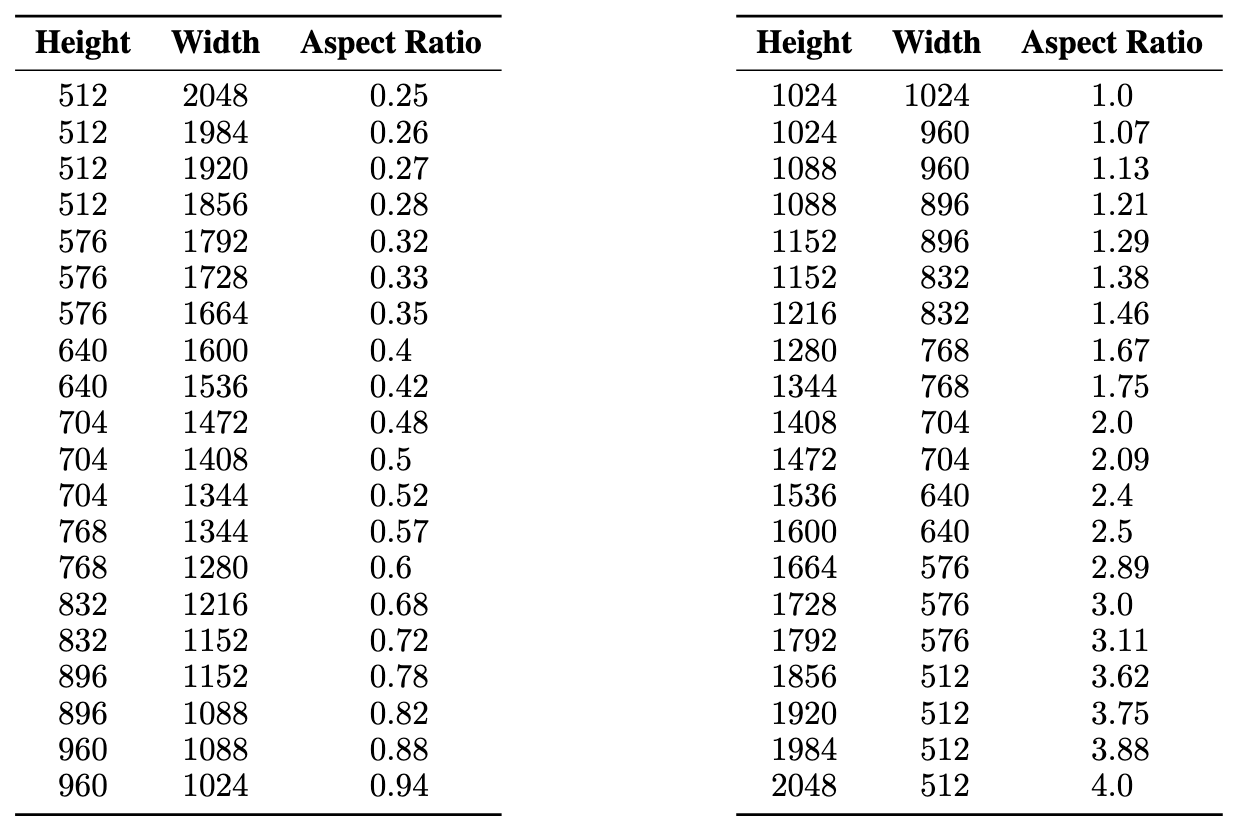
在训练阶段,每个batch中的数据都来自同一个桶,每个训练step会变换具体采样的桶。除此之外,SDXL还会将桶的size作为额外的Condition输入到模型中,输入方式和前文提的两种Condition类似。
1.4 Improved Autoencoder
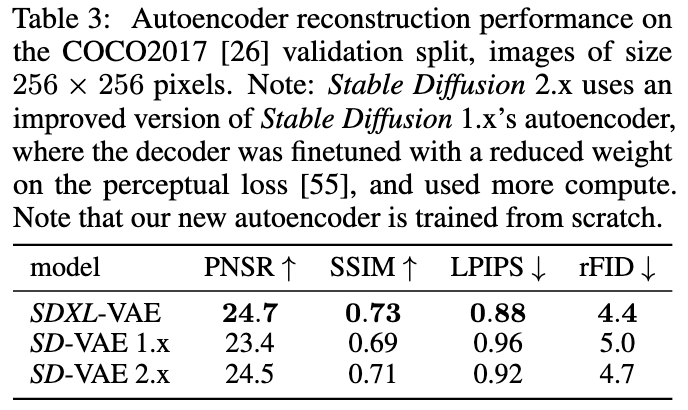
SDXL本身是一个LDM,对于压缩感知阶段使用的VAE,SDXL也进行了优化:
- 采用更大的batchsize进行训练(9->256)
- 采用指数滑动平均方式来更新权重
优化后的VAE在指标上优于原VAE:
1.5 Putting Everything Together
将以上改进结合,本文训练了SDXL,其是一个多阶段训练流程:
- 以256x256分辨率,在一个内部数据集上预训练了一个基础模型,其batchsize为2048,一共训练了600000步,采用了SizeCondition和CropCondition。
- 以512x512分辨率进一步微调了200000步。
- 在大约1024x1024的像素区域尺寸上,采用Multi-aspect Training策略再微调了200000步,设置offset-noise level为0.05。
完成以上训练后,SDXL的在局部细节上做的并不好:

为了进一步提升样本的质量,在同一个Latent Space,本文额外训练了一个LDM作为Refine Model,该LDM专门处理高质量、高分辨率的数据。SDXL参考SDEdit中的噪声去噪过程,在Latent Space中对图像样本添加噪声,再通过模型进行噪声的去除。参考eDiff-I,本文将该LDM专家化并作用于前200个离散噪声级别上。这意味着Refine Model专注于在生成过程中的早期阶段,即噪声较多的阶段,以提升生成样本的质量。
在推理阶段,本文会首先从Base SDXL模型中获取Latents,然后再使用Refine Model进行去噪。
Refine Model可以在一定程度上提升SDXL生成样本的细节质量:

3. Future Work
论文中提出了几个未来可能的研究方向和可以进一步探索的点(来自https://papers.cool/arxiv/2307.01952):
- 单阶段生成过程:目前SDXL使用两阶段方法(基础模型加细化模型)来生成高质量的样本,未来研究可以探索如何将这一过程合并为一个单阶段生成过程,以减少内存占用和提高采样速度。
- 文本合成能力的提升:尽管SDXL的规模和文本编码器有所提升,但进一步改进文本渲染能力仍然是一个值得探索的方向。可以考虑使用字节级分词器或进一步扩大模型规模来实现这一目标。
- 架构的改进:论文中提到了对基于变换器的架构(如UViT和DiT)的初步实验,但没有发现立即的好处。未来可以通过仔细的超参数研究来探索是否能够扩展到更大的以变换器为主的架构。
- 推理成本和采样速度的降低:SDXL在图像质量上的提升带来了更高的推理成本和更慢的采样速度。未来的工作可以集中在减少推理所需的计算资源和提高采样速度上,例如通过指导、知识和渐进式蒸馏技术。
- 连续时间EDM框架:当前的模型是在离散时间形式下训练的,需要偏移噪声才能获得美观的结果。未来的模型训练可以探索使用EDM框架,因为它的连续时间形式允许更大的采样灵活性,并且不需要噪声调度校正。
- 社会和种族偏见的处理:由于训练数据集可能引入社会和种族偏见,未来的研究需要解决这些问题,确保模型的负责任和道德部署。
- 概念渗透问题的解决:在生成包含多个对象或主题的样本时,模型可能会遇到概念渗透现象。需要识别和解决这种情况,以提高模型在复杂场景中准确表示单个对象的能力。
- 长文本渲染的改进:模型在渲染长文本时仍然存在困难,未来的研究可以通过开发更好的文本生成技术或扩大模型规模来解决这个问题。
这些潜在的研究方向将有助于进一步提升文本到图像合成模型的性能,并解决当前技术的局限性。

文章评论